Many blog articles and LinkedIn posts claim that Knowledge Graphs and Language Models are a good match and that potential future products that combine both worlds will be even more powerful. I work in that field because I strongly believe in that idea, but it requires more than a blog post with theoretical claims to convince people. That’s why I wrote this blog post with easy-to-understand examples that will work in the upcoming 8.2 release of TopBraid EDG and only require a basic understanding of SPARQL, JavaScript, and SHACL. If I haven’t sparked your interest yet, let me tell you that everything will be explained based on examples with wombats!
Wombats and Knowledge Graphs: Nature in Data

Before we start to delve into the topics of Knowledge Graphs and Language Models, let me tell you something about wombats. Wombats are short-legged marsupials from Australia, meaning they belong to the same group of animals as koalas and kangaroos, with a unique reproduction strategy. Young Joeys are born in a relatively undeveloped state, nurtured in a pouch in their mom’s belly. Usually, the opening of pouches faces upward. However, wombats’ pouches face backward, preventing soil from getting inside while they dig burrows, aka their homes. To effectively mark their territory using poops, wombats developed yet another unique strategy: produce cube-shaped poops so they won’t easily roll away like the normal round ones. The poop is placed at exposed places to let other wombats know when they enter someone’s territory. They are quite intelligent animals indeed.
Now, let’s put all these facts into a Knowledge Graph. First, we can create a taxonomy where we add wombat as a concept:
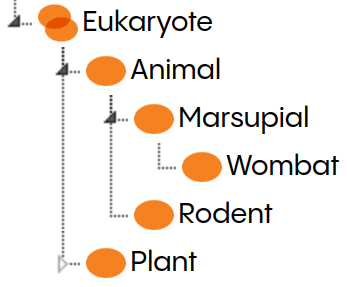
We can add some of the information as a description to the concept. I copied some snippets from Wikipedia:

Besides adding information as literal as a textual description, there is a more explicit way to add information. That wombats have cube-shaped poop can be expressed as a SHACL rule:
1 | @prefix animals_and_plants_taxonomy: <http://example.org/taxonomies/Animals_and_Plants_Taxonomy#>. |
This rule is applied for all instances of a Wombat and creates a new triple with the predicate poop:shape and as object value poop:Cube.
Let’s leverage that information in a few use cases.
From Language Models to Knowledge Graphs: Finding “Wombat”
Imagine you want to create a new instance in your Knowledge Graph. You have to select the type of the instance, but you can’t remember the term Wombat. Luckily, you read a blog post about them a while ago, and you clearly remember that they are short-legged marsupials with a backward-facing pouch. A language model combined with a vector store could be leveraged for that use case. That’s quite easy to configure in TopBraid EDG. That was done already for our taxonomy so that we can translate the following text into a SPARQL CONSTRUCT query:
“Yuki” is a “marsupial with short legs and a backward-facing pouch.”
1 | PREFIX ai: <http://ai.topbraid.org/ai-service#> |
As you can see, I added some additional filters to the query. First, only search results with a score higher than a given threshold should be returned. Second, only the concept nodes without children are selected. That’s the benefit of running the vector search in SPARQL, where these filters can be combined into a readable and compact query.
Here are the generated triples that describe the new Yuki resource:
1 | @prefix animals_and_plants_instances: <http://example.org/data-graphs/Animals_and_Plants_Instances#>. |
OK, we’ve created a resource in our Knowledge Graph with the help of a language model and a vector store. But does it also work in the other direction? Can a Knowledge Graph help a language model to do its work?
Wombat Wisdom: Using SHACL Rules to Teach LLMs About Poop
Compared to language models, Knowledge Graphs shine when it comes to readable rules that can be applied for reasoning. LLMs are capable of learning rules, but the list of learned rules is more or less a black box. The intermediate step of generating triples with SHACL rules allows a human in the loop to verify the result of the rules.
Let’s apply the SHACL rule we defined earlier. I’ve created a small ADS script to execute the rules in a temporary sandbox graph, which only returns the newly generated triples. Here is the script:
1 | function executeRulesSandboxed ({ imports, triples = [] } = {}) { |
As expected, we get a new triple that describes that Yuki has cube-shaped poop.
1 | @prefix animals_and_plants_instances: <http://example.org/data-graphs/Animals_and_Plants_Instances#>. |
Now, we can reach out to our LLM with the new information to ask questions about Yuki. Therefore, we combine the information generated by the SHACL rule and the prompt containing our question. This approach is also known as RAG. To keep this example simple, I copied the plain Turtle without namespaces. A more error-proof approach should be used for live applications.
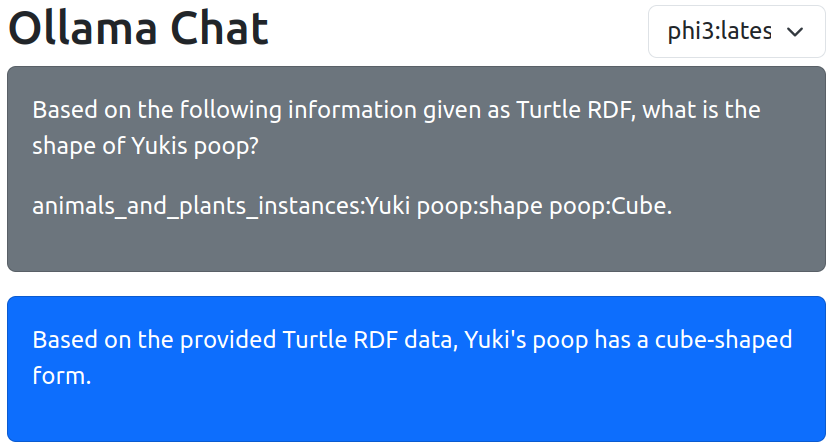
And now, we can see that the LLM was able to use the information from our SHACL rule to answer the question of what shape Yuki’s poop has.
I’ve used my own small Web UI for a local-hosted Ollama with the Phi-3 model. The type wombat triple was skipped to rule out that the LLM does the reasoning based on that triple rather than based on the result of the SHACL rule.
That closed the circle in our example from a language model for a vector search via SHACL rules to LLMs and RAG. But there is more. Let’s dig deeper.
Wombat Knowledge: Tackling Uncertainty with Probabilities in Graphs
A very important topic I want to address is score/probability. It will become more important in the field of Knowledge Graphs with the increasing use cases overlapping with language models and other machine-learning algorithms. We need to get used to having probabilities everywhere in neuro-symbolic AI applications. It is already part of Knowledge Graphs, but most of the time, it’s implicitly 1.0.
In our example, the vector index search returns a score/probability value we can access in our SPARQL query. The score can be attached to all triples based on the search result. But we can go even further. All triples inferred by the SHACL rule should have the same score. I’ve extended the ADS script to attach the score value to all generated triples.
1 | function executeRulesSandboxed ({ imports, score, triples = [] } = {}) { |
As you can see, besides the triple inferred by the rule, there is a triple for the score attached to the reified subject.
1 | @prefix ai: <http://ai.topbraid.org/ai-service#> . |
Adding scores as reified attachments to the triples has the benefit that there is no need to verify the triples during the creation process. There are different options for how to handle probability later in the process. Once the triples are used, they can be shown to the user who is responsible for verifying them. Or, an LLM could be fine-tuned to understand score values and answers in a language that covers uncertainty.
Further Improvements for Wombat Prompts with Knowledge Graphs
Above was just a short example of how language models and Knowledge Graphs can benefit from each other. There are many more possibilities.
An obvious next step in the shown example would be combining the steps that generate the triples, run the rules, and inject additional information into the prompt. All of that could be done on the fly. Let’s assume we have the following prompt:
Yuki is a wombat. What’s the shape of Yuki’s poop?
The resource Yuki with the type wombat could be created from the prompt. The SHACL rule would then generate the poop shape triple. All triples can be added as additional information to the prompt to improve the quality of the LLM response.
Not Only for Wombats: Optimizing RAG Data with Knowledge Graph Rules
Putting data into a Knowledge Graph and fetching it later to process it with an LLM is not just another persistent layer for RAG data. Rules add an intelligent and powerful data processing layer to it. Another obvious match for Knowledge Graphs and RAG is GraphRAG for further optimizations.
Get Your Rules Out of the Burrow: LLMs vs Knowledge Graphs
Some may say that creating rules in a Knowledge Graph requires a lot of work, and using an LLM is much easier. However, fine-tuning the LLM would be required if your rules are derived from private data. Still, the rules would be inside a black box. But LLMs can help build rules with a human in the loop to speed up the process.
Further Reading
If you want to dive deeper into the topic of RAG, I can recommend the blog post How to Implement Graph RAG Using Knowledge Graphs and Vector Databases written by my colleague Steve Hedden and check out the discussion on LinkedIn.
Regarding probability, vector search, and embeddings, I may refer to my previous blog post, which covers some existing problems in that field and an approach to solving these problems.